Canonical Issues in SEO
Canonical Issues in SEO
Canonical issues arise when there are multiple versions of the same page available on your website, confusing search engines about which one to rank. These issues can lead to duplicate content penalties, reduced crawl efficiency, and ultimately lower SEO rankings.To resolve these issues, you need to identify them and implement strategies to guide search engines to the most authoritative version of a page. Here’s a step-by-step guide on how to resolve canonical issues and improve your SEO rankings.
1. Understand Canonicalization in SEO
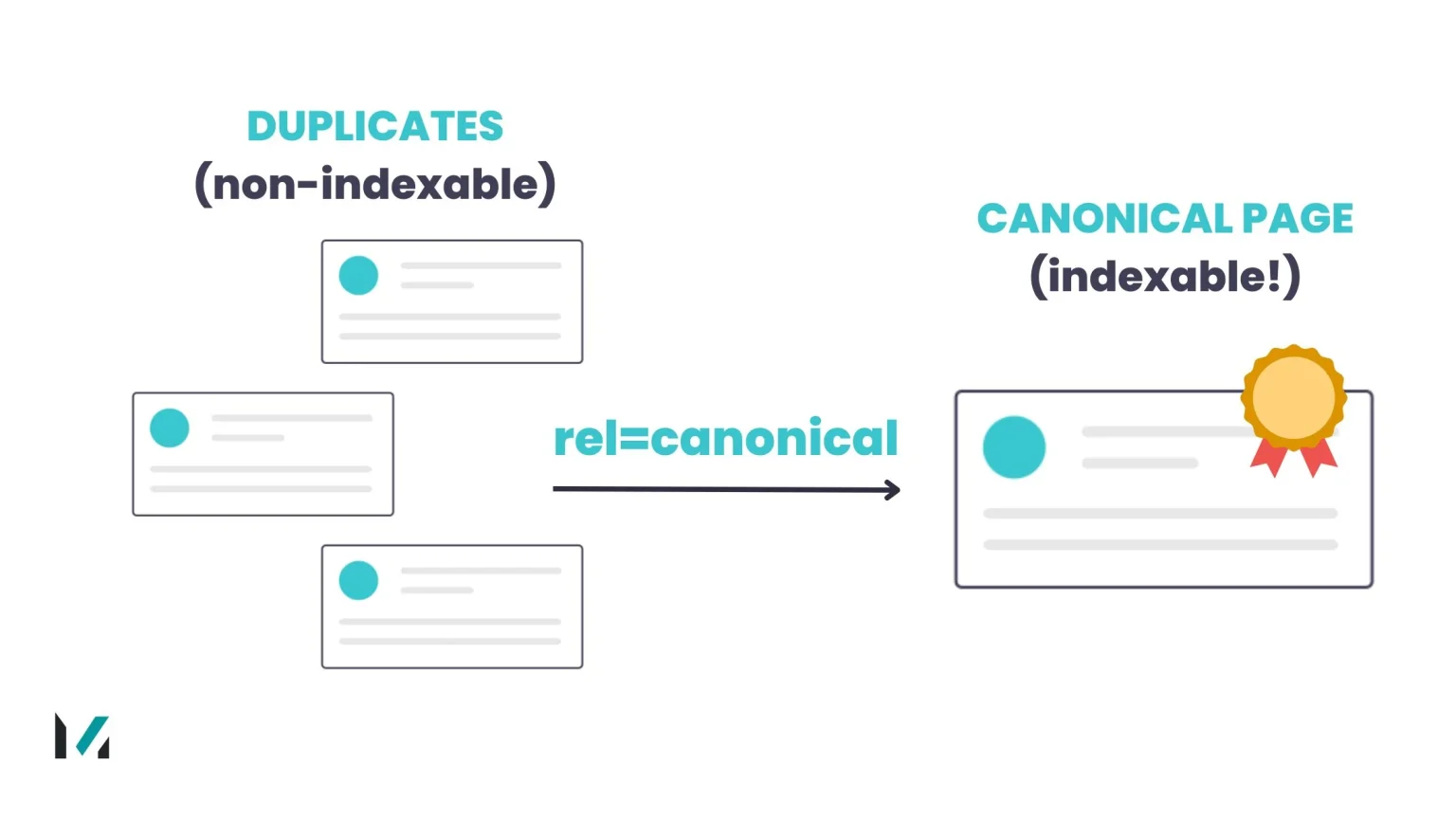
The process of choosing the preferable version of a page when there are multiple pages with the same or comparable content is known as canonicalization. Tells search engines which version to indexed, and actively prevent duplicate content from damaging your SEO rankings.
For example, a product page might be accessible via both https://example.com/product and https://example.com/product/?ref=123. The correct approach is to choose one version as the canonical URL and use a rel=”canonical” tag to point to that preferred URL.
2. Identify Canonical Issues on Your Website
Before resolving canonical issues, you must identify them. Here are a few common causes:
- Duplicate content: Refers to Multiple pages that contain the same or comparable content are called duplicate content.
- HTTP vs. HTTPS: Both versions of a page (with and without HTTPS) are indexed.
- www vs. non-www versions: The website accessible with or without “www” in the URL.
- Sort parameters or tracking codes: URLs that differ only due to query parameters, such as https://example.com/product?color=red and https://example.com/product?color=blue.
Use tools like Google Search Console, Screaming Frog, or Sitebulb to crawl your site and find pages with duplicate content. Look for issues related to URL variations and parameter discrepancies.
3. Implement Canonical Tags Properly
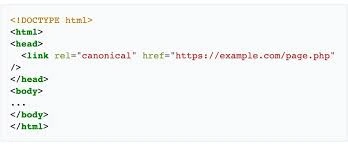
Once you’ve identified the problematic URLs, the next step is to implement the rel=”canonical” tag. This tag should be added to the <head> section of the HTML of the non-preferred page to point to the preferred version.
For example: <link rel=”canonical” href=”https://example.com/preferred-page” />
4. Consolidate Duplicate Content Using 301 Redirects
If you have duplicate pages that don’t serve any unique purpose, consolidate them by using 301 redirects to redirect users and search engines to the preferred page. Consider redirecting the non-canonical pages to the canonical version of a product page if there are multiple versions (e.g., one with a “?ref=123” parameter).

This prevents the search engine from crawling unnecessary duplicate content, improving crawl efficiency and ensuring that all ranking signals are concentrated on the preferred page.
5. Set Preferred Domain (www or non-www)
Make sure your website is accessible under only one domain version: either with or without “www.” Search engines may treat example.com and www.example.com as two different sites, resulting in duplicate content problems.
You can specify your preferred domain in Google Search Console by selecting one as the default. To ensure users land on the preferred version, actively redirect them using 301 redirects
6. Use HTTPS Consistently
If your website supports HTTPS, ensure that the secure version (with HTTPS) is the canonical version. In the past, some websites had both HTTP and HTTPS versions, leading to potential duplicate content issues. By enforcing HTTPS throughout your site, you consolidate ranking signals and improve security, which is also a ranking factor.
7. Fix URL Parameters
If your website uses URL parameters (e.g., for tracking or filtering content), it can create multiple versions of the same page. Search engines may interpret these as separate pages, leading to duplicate content problems.
To resolve canonical issues this, you can:
You can use the rel=”canonical” tag to designate the main version of a page.
Use Google Search Console to tell Google whic characteristics to ignor or handle uniquely. Avoid creating unnecessary URL variations by minimizing tracking parameters in URLs.
8. Monitor Your Site Regularly
Resolving canonical issues is not a one-time task. Search engines constantly crawl your website, and new duplicate content issues can arise over time. Regularly monitor your site’s performance using tools like Google Search Console or Screaming Frog, and resolve any new canonical issues promptly.
9. Avoid Overuse of Canonical Tags
Canonical tags are necessary, but using them excessively can confuse search engines. Ensure that each page on your site has only one canonical tag, and it points to the correct page. Misleading or incorrect canonical tags can harm your SEO efforts rather than help.
10. Test Your Changes
After implementing changes, actively test your website to ensure the canonical issues are resolved. You can use tools like the URL Inspection tool in Google Search Console to check if Google has correctly recognized a page’s canonical version.
Conclusion of Canonical Issues in SEO
Resolving canonical issues is essential for improving your SEO rankings and avoiding penalties for duplicate content. By using canonical tags correctly, implementing 301 redirects, consolidating duplicate content, and ensuring consistency in the domain and HTTPS usage, you can help search engines understand which pages are the most important for indexing and ranking. Regular monitoring and testing will ensure that your website stays in top shape for optimal SEO performance.

